Case Studies
Parsl is being used by a wide range of researchers across many scientific domains. Below we highlight recent use of Parsl in some of these research domains.
Chemistry
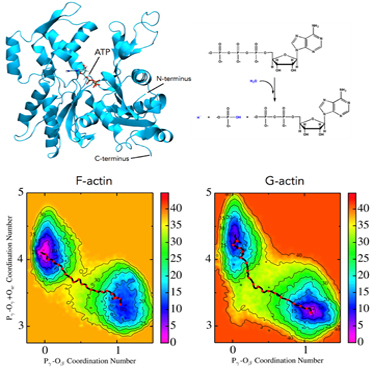
Researchers at the University of Tampa have developed and implemented a new flexible monomer two body carbon dioxide potential function to address the gas phase properties of CO2 at high levels of quantum mechanical theory. As part of this work they have focused on understanding the vibrational structure of small clusters of CO2 molecules with the aforementioned potential function.
These researchers have used Parsl to parallelize the dynamics simulations, in order to increase the computational efficiency and improve the statistical sampling. Since the methodology is implemented using the Python scripting language and a Jupyter notebook, parameters can be easily modulated according to the type of simulation needed or to the desired output data.
Physics
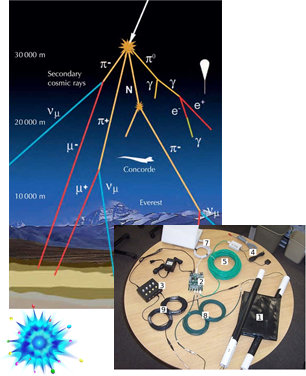
QuarkNet is an NSF-funded program at the University of Notre Dame that provides professional development opportunities for high school science teachers by connecting them to a nationwide network of researchers and experiments. One of QuarkNet's projects is a set of webapps known as e-Labs. The e-Labs gather real data from scientific experiments, including the CMS detector of the Large Hadron Collider and the LIGO gravitational wave detectors, and make it available to students through a set of analysis exercises designed for use in the high school science classroom.
The most widely-used e-Lab is the Cosmic Ray e-Lab, which presents students with data on cosmic ray muon events in the earth's atmosphere. QuarkNet is developing Jupyter notebook-based versions of this e-Lab's data studies that use Parsl to orchestrate the execution of the programs that perform the demanding computation required to provide flexible and fast cosmic ray data analysis. The combination of Parsl and the Jupyter environment will allow QuarkNet to open their existing analysis code to a wider audience and to create new tools for data science education.
Cosmology
The Dark Energy Science Collaboration (DESC) seeks to understand the nature of dark energy and further our understanding of the acceleration of the expansion of the universe. DESC aims to leverage the huge dataset produced by the Large Synoptic Survey Telescope (LSST) to measure how Dark Energy behaves over time. Members of DESC are using Parsl to develop workflows for image generation, weak lensing, and modeling galaxy clusters.
Biology
Genome analyses represent a crucial processing step for understanding a wide range of disease. Unfortunately, analyzing DNA sequencing data is computationally intensive, requires multiple processing steps, and the range of tools suitable for each stage is rapidly growing.
Researchers at the National University of Singapore and the University of Chicago have developed SwiftSeq: a large-scale next generation sequencing analysis pipeline that combines a myriad of processing tools and provides for highly parallel execution on clouds, clusters, and supercomputers. The SwiftSeq pipeline is being implemented in Parsl to manage parallelism of processing tools and sequencing data.
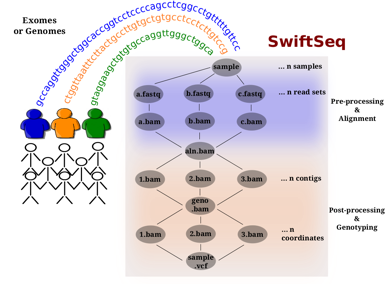
Materials Science
Materials scientists at Argonne National Laboratory are interested in understanding and modeling “stopping power,” defined as a “drag” force experienced by high speed protons, electrons, or positrons in a material. Stopping power has applications in areas like nuclear reactor safety, solar cell surface adsorption, and proton therapy cancer treatment. It is also critical to understanding material radiation damage.
Time-dependent density functional theory (TD-DFT) offers an accurate way to compute stopping power: it is highly parallelizable, parameter-free, and can accurately reproduce experimentally-measured stopping powers. However, TF-DFT computations and expensive, and scientists increasingly need to easily access stopping power for many different types of materials in all possible directions, and even ascertain the effects of defects on the stopping power. Thus, Argonne researchers are using machine learning to extend TD-DFT’s capabilities. Specifically, they have implemented a Parsl-based workflow that processes data stored in the Materials Data Facility (MDF) to create surrogate models for TD-DFT.
Information Extraction
The amount of scientific literature published every year is growing at an overwhelming rate (estimates suggest up to 1.8 million articles per year). Therefore, the amount of important findings (e.g. experiment results) locked in tables, figures and text of various format is staggering. Researchers at NIST and the University of Chicago are developing automated methods for extracting scientific facts from publications.
Parsl is being used to parallelize complex information extraction workflows. These workflows combine existing NLP tools, semi-supervised word embedding models, named entity extractors, and named entity classifiers. The workflows are executed on supercomputers at Argonne National Laboratory to process tens of thousands of scientific publications in parallel.