Passing Complex Data Structures in Computational Workflows – A Big Problem with a Simple Solution
30 Nov 2023 - Ben Clifford (Parsl) and Andrew S. Rosen (University of California, Berkeley)
The Big Picture
Andrew, a Miller Research Fellow at UC Berkeley and incoming Assistant Professor at Princeton University, has been developing an open-source software package called the “Quantum Accelerator,” or quacc for short. quacc is a Python library that makes it easy to write and run computational materials science workflows using a wide variety of underlying simulation packages. The workflows built into quacc can be used to accelerate the discovery of novel materials to address the countless clean energy and sustainability challenges facing our planet.
![]()
Figure 1: quacc logo
quacc leverages Parsl as one of the several supported tools for workflow orchestration and dispatching, allowing both developers and users to focus on the science rather than the data engineering while also being able to take full advantage of next-generation HPC resources. As the codebase and user base grew, it became clear that there was a crucial limiting factor in how most workflow management tools (including but certainly not limited to Parsl) handled the passing of data from complex data structures between compute tasks. We discuss this challenge below and how the open-access, collaborative, and welcoming environment that Parsl supports was able to rapidly address this bottleneck, ultimately making computational materials discovery campaigns even more powerful than ever before.
A Representative Challenge
Consider a very time- and compute-intensive workflow consisting of two steps: A→B.
In Step A, we run some simulation on the HPC machine that returns a large, nested data structure summarizing the details of that simulation. Perhaps it looks something like the following:
output = {
"inputs": {"accuracy": "high", ...},
"results": {"is_converged": True, "energy": -21.2, "forces": np.array([[0.5, 1.0, 0.5], [0.1, 0.3 ,0.01]])},
…
}
In Step B, we want to do some analysis or operation on a subset of that computed data. For the sake of this example, we can pretend it’s as follows: take the forces, F, and find the largest net force: |F|_{max}.
There are many ways to write this, each highlighting a problem.
Problem 1: Concurrency
The first approach is as follows:
@python_app
def simulate(accuracy = "high", ...) -> dict:
# do some complex simulation
return output
@python_app
def get_max_force(forces) -> float:
import numpy as np
return np.linalg.norm(forces, axis=1).max()
This is exactly how you’d write it in regular Python, except that the magical @python_app decorators have been added.
If the developer or end-user tries to write a workflow with these two compute tasks, it’d look like:
output = simulate(...).result()
max_force = get_max_force(output["forces"])
Note the call to .result() in the first PythonApp. This blocks all other computation from being performed since the workflow needs the result of the simulate task to know how to fetch the “forces” entry from the data structure. However, if you were to run 1000 of these workflows in parallel (e.g. via a for loop), you now have a problem. You can’t. They will wait for the first one to finish due to the blocking .result() action. This is the problem of performance (concurrency).
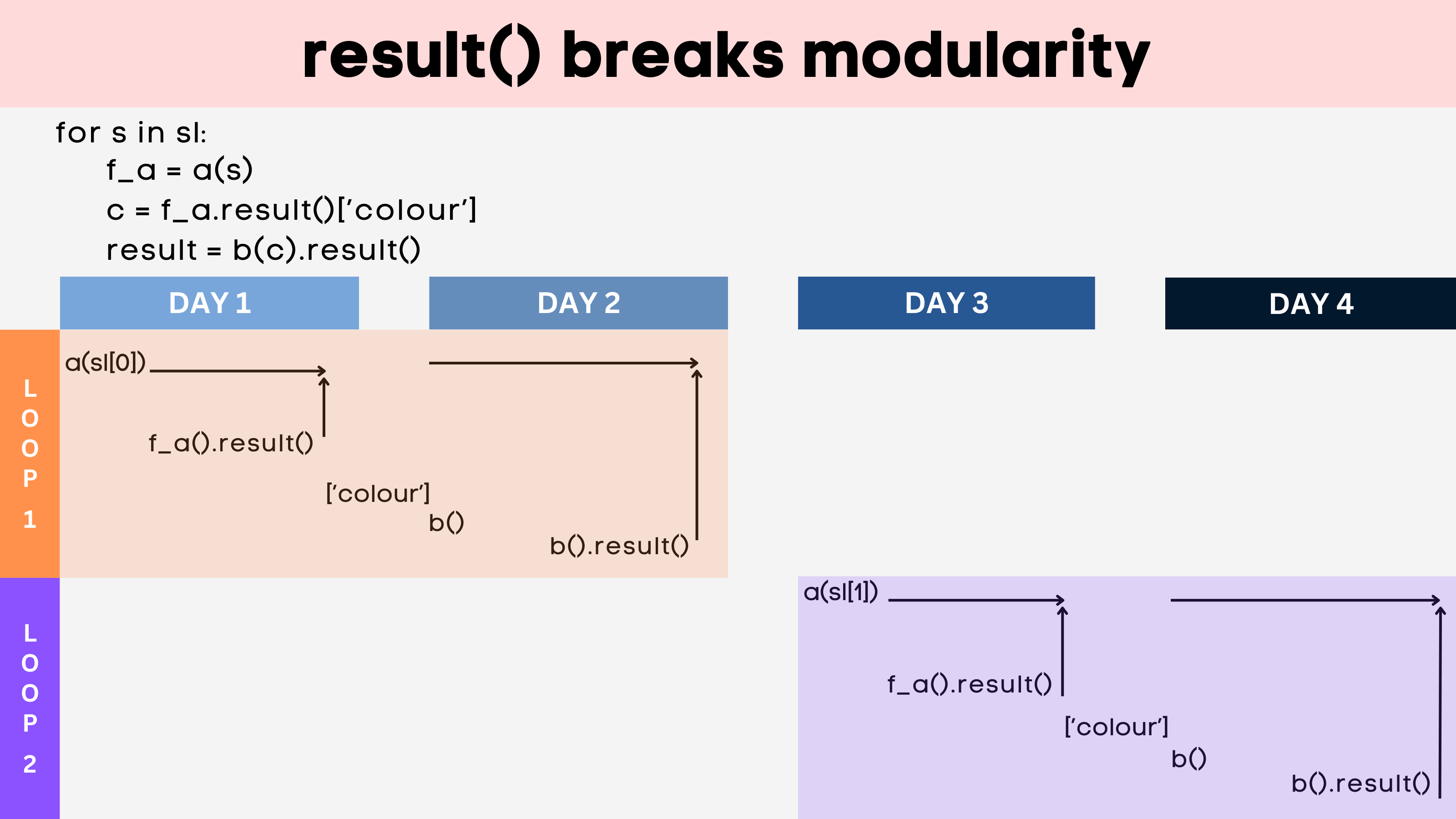
Figure 2: A diagram of the performance problem described in this section. (Credit: Ben Clifford and Sophie Bui)
Problem 2: Code Reusability
To circumvent the blocking call to .result(), the wise-thinking developer can rewrite their individual PythonApps as follows:
@python_app
def simulate(accuracy = "high", ...) -> dict:
# do some complex simulation
return output
@python_app
def get_max_force(simulation_output) -> float:
import numpy as np
forces = simulation_output["forces"]
return np.linalg.norm(forces, axis=1).max()
output = simulate(...)
max_force = get_max_force(output)
Here, we avoid the need to call .result() by passing the data structure from the simulation task directly as the input to the force computation. Parsl is smart enough to know how to handle AppFutures being passed between PythonApps, and we have taken advantage of that.
There are now no problems with concurrency. However, this has come at a cost: we have intentionally designed the get_max_force function in such a way that it is no longer a general mathematical operation. It is intrinsically tied to the data structure from the previous simulate task. If the developer wishes to use this get_max_force() function elsewhere in their codebase, it relies on a specific input type that might not be broadly relevant.
This gets at the heart of a development problem: we should be writing functions (and, therefore, PythonApps) as general and discrete units of work. The above solution, while performant, sacrifices composability. It also is a philosophical bother. One of the great advantages of Parsl is that you can often write your Python code as you normally would, the only major change being that you decorate your function with @python_app. However, that principle falls apart here. The developer is now writing their functions with Parsl in mind, which can be a burden.
Problem 3: Composability
This issue is closely tied to the one above. However, in this scenario, let’s assume that the codebase ships many different types of simulations, each of which returns varying types of data structures that the user can combine in their own way. For instance, consider:
@python_app
def simulate2(...) -> dict:
# another complex simulation
return {"results": {"final_forces": np.array([[0.5, 1.0, 0.5], [0.1, 0.3 ,0.01]])}}
If the user wants to calculate |F|_{max} but this combined two-step workflow wasn’t already provided in the codebase, what do we do? We can’t use our get_max_force function anymore because our “forces” key isn’t in the resulting dictionary of the simulation task.
The developer could anticipate this and update get_max_force to pull the forces from one of several possible keys, but this quickly becomes unwieldy and prone to error. The user could contribute to the codebase to add a new workflow addressing this custom data structure, but this too becomes unwieldy.
In short, there are simply too many ways that end-users (and developers) can combine tasks. There needs to be a better way.
How Parsl Addresses This
The solution implemented in Parsl is elegant and Pythonic:
@python_app
def simulate(accuracy = "high", ...) -> dict:
# do some complex simulation
return output
@python_app
def get_max_force(forces) -> float:
import numpy as np
return np.linalg.norm(forces, axis=1).max()
output = simulate(...)
max_force = get_max_force(output["forces"])
Even though output is an AppFuture that can normally not be indexed (since the available keys aren’t known until the simulate task completes), Parsl will “lift” the index into the @python_app call and implicitly know to return the [“forces”] query only when the AppFuture is resolved.
This addresses the concurrency concerns because .result() never needs to be called.
This addresses the code reusability concern because now the get_max_forces task is written like you would expect: it takes forces in, and it returns a float. It is not custom-made for a given previous step in mind.
This addresses the composability concern because now the end-user can apply get_max_forces on many other kinds of simulation tasks, regardless of the resulting data structure.
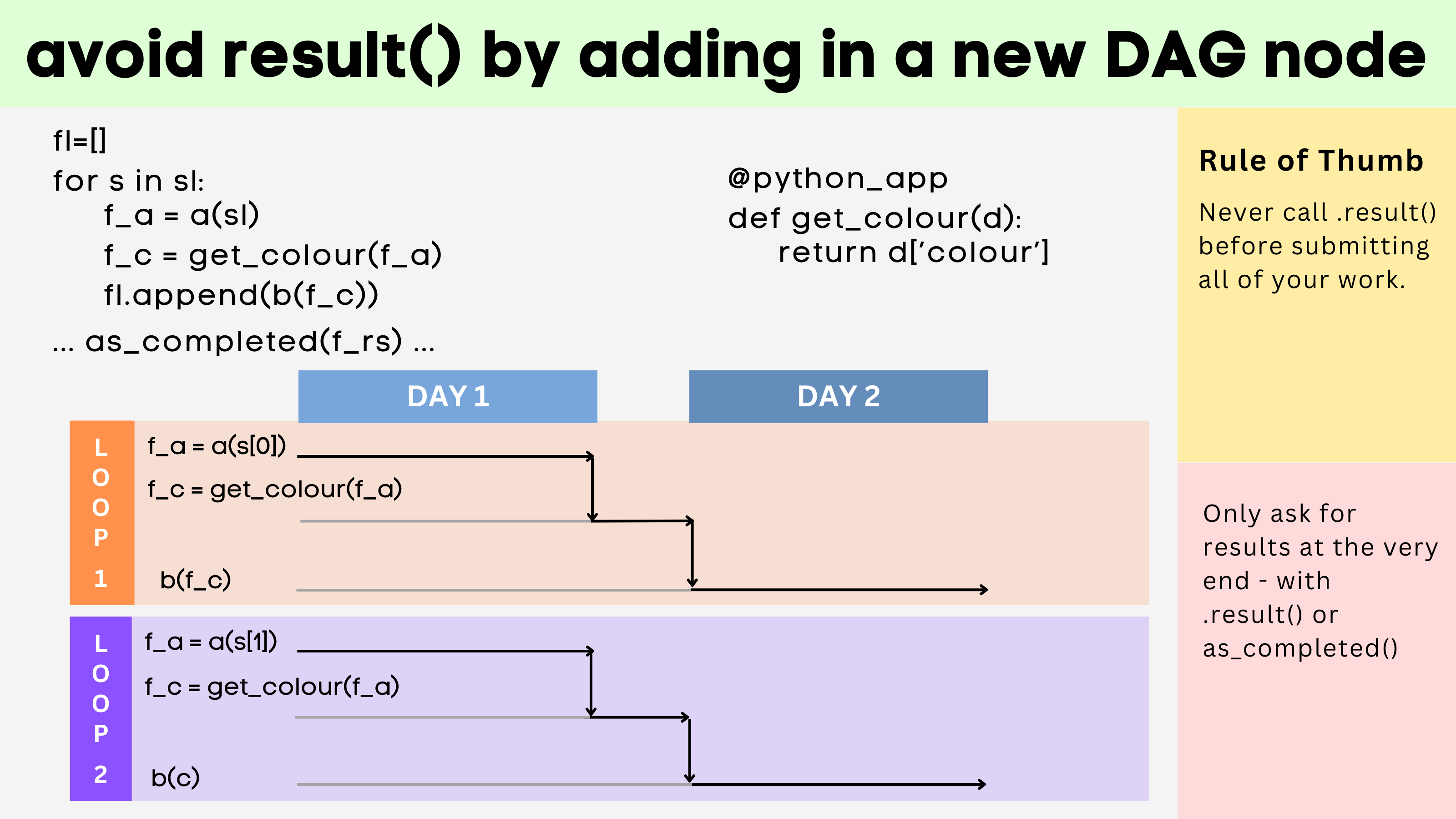
Figure 3: A diagram of the solution to the performance challenge presented in problem 1. (Credit: Ben Clifford and Sophie Bui)
Scientific Impact
With this simple and elegant update to Parsl, the quacc code for computational materials discovery has immediately benefitted from performance gains related to increased task concurrency. Additionally, the code development and maintenance burden has been drastically improved, which is critical for the health of an open-source software project.
While there are numerous workflow orchestration tools to pick from, Andrew reports that Parsl stands out as being particularly welcoming to the diverse needs of its users, as exemplified by the rapid implementation of this new feature. The engaging community of developers and users alike is an added bonus.
ℹ️ For more information on quacc, check out its website and GitHub repo.