Getting the first end-result faster with task priority
17 Nov 2025 - Ben Clifford
In an earlier post, I talked about using task priorities to minimise wasted time in a batch job. In this post, I’ll talk about using the same mechanism for a different goal: getting the first end-result faster.
A toy workflow
The example workflow I’m going to use here consists of 100 independent copies of a 4-task diamond-DAG, each task being random duration between 1 and 2 seconds.
The diamond DAG workflow consists of these four tasks, which you could imagine as a pre-processing step, a parallel step of two tasks and a summarisation step. This is a stylised form of a common workflow pattern.
fa = a()
fbl = b_left(fa)
fbr = b_right(fa)
fc = c(fbl, fbr)
Because the DAGs are independent, they could be run completely separately, but running them all together in one workflow lets them share the same pilot jobs and interleave their work.
Goal
I’ll invent a goal for this post: we want the end results (the output of the C tasks) to arrive fast/early. There are a couple of practical motivations for that: the intermediate tasks might generate a lot of data that can be deleted once the C task has completed; the output data might be flowing further into a pipeline (perhaps human analysis, perhaps more processing) and we want to keep that flowing smoothly.
What happens now is highly dependent on how the executor you are using decides to run tasks.
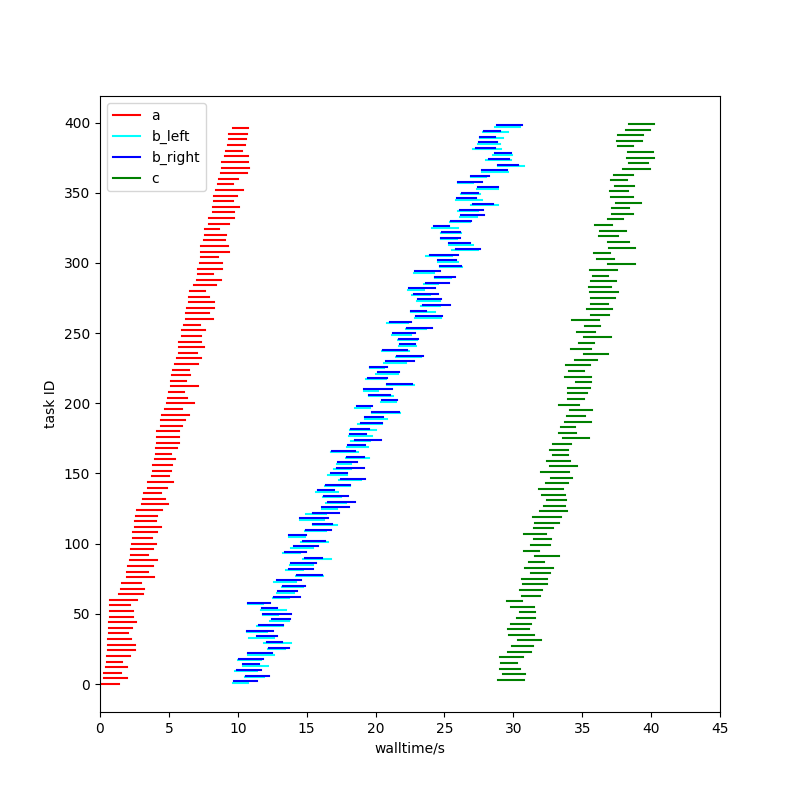
For example, using the High Throughput Executor, tasks are executed roughly in the order in which their dependencies become completed, the order in which they become ready to run. TaskVine runs things in a more arbitrary order, more of which later.
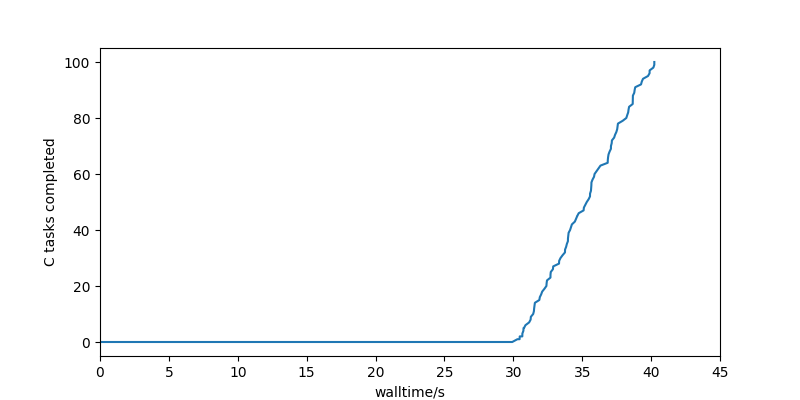
The High Throughput Executor default order is particularly degenerate as far as the completion goal is concerned: it runs all the A tasks first, then all the B tasks, and finally all the C tasks, giving no completions at all for most of the run, and then a burst at the end.
I’m going to talk about two (maybe three) prioritisation schemes to fix that.
Prioritising by depth
For the first scheme, tasks are prioritised to make tasks later in the task graph run first. Initially, only the first layer (A) tasks will be able to run, but as soon as one is completed, it will unlock some B tasks, which will in this scheme be run next (in preference to other A tasks), and those in turn will unlock (and thus complete) a C task much sooner.
Those two graphs above now look like this:
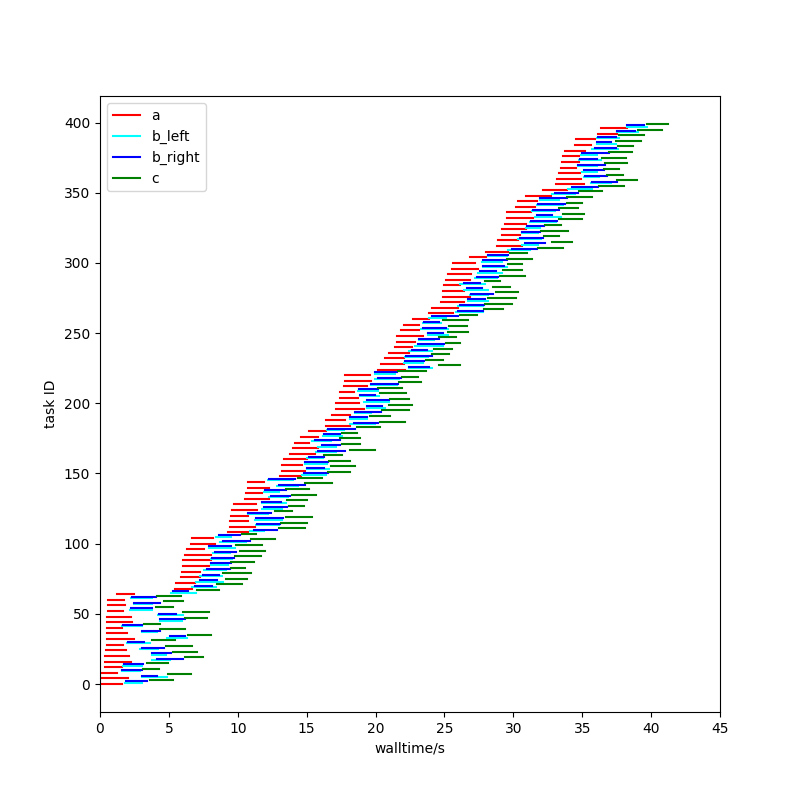
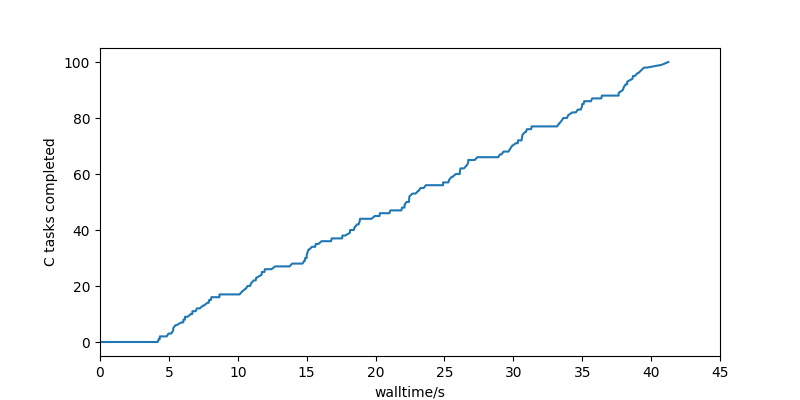
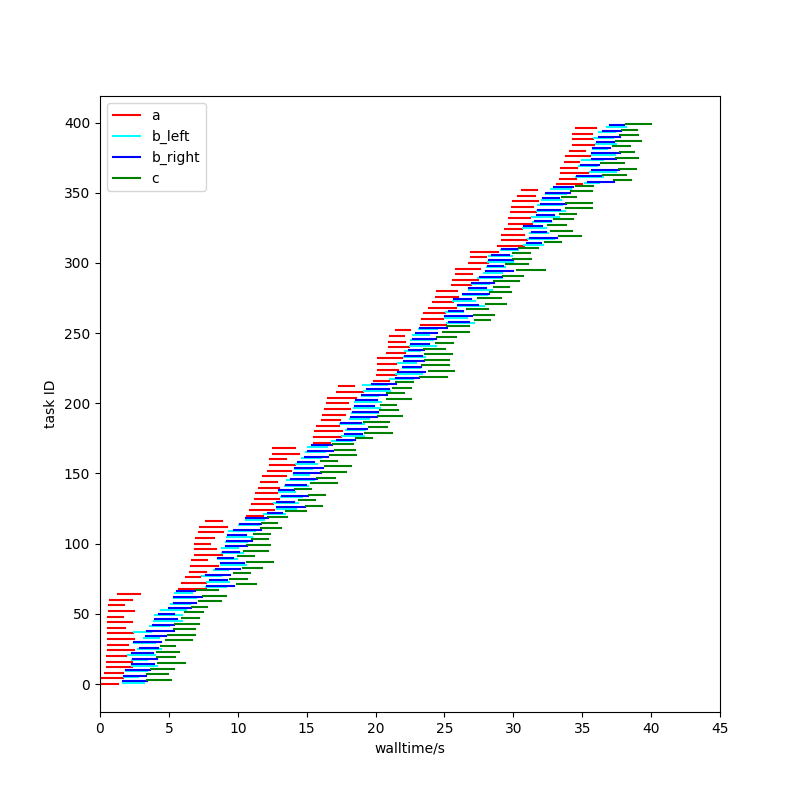
The time to first completion has gone from 30 seconds (75% of the way through the run) to 4 seconds (10% of the way through the run).
Hopefully on the task plot you can see that a wave of red A tasks starts (because there’s nothing else to do), but as those complete blue (B) and green (C) tasks are run instead of more red A tasks. Only when those are exhausted does another wave of red A tasks start.
The code for prioritisation by task type looks like this:
fa = a(parsl_resource_specification={"priority": 3})
fbl = b_left(fa, parsl_resource_specification={"priority": 2})
fbr = b_right(fa, parsl_resource_specification={"priority": 2})
fc = c(fbl, fbr, parsl_resource_specification={"priority": 1})
The C tasks are the most important to run, the B tasks (two kinds) next, and the initial A tasks are least important: working from the bottom of the DAG upwards.
Prioritising by task group
Here’s a totally different way of assigning priorities, that gives quite similar results - at least on this workload.
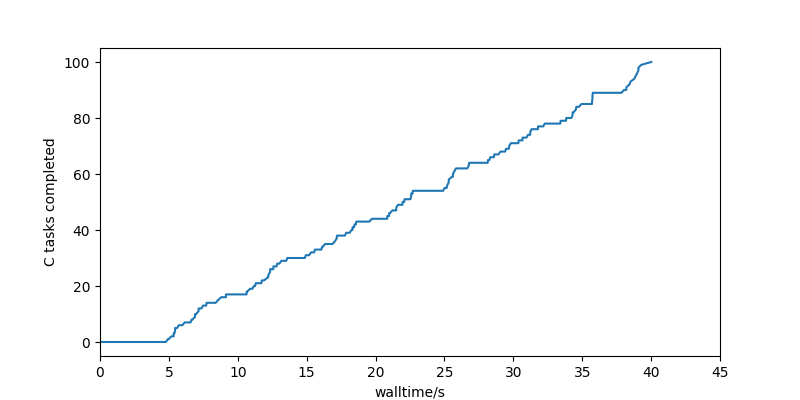
In this run, tasks are prioritised by the identity of the diamond-DAG that they belong to: all 4 tasks (A, B_left, B_right and C) that belong to the first diamond-DAG are given priority 1, all 4 tasks of the next one are given priority 2, and so on up to the 100th.
That expresses a different goal through the language of priorities. In the previous section, the priorities translated the goal: try to run the deepest parts of the workflow. This second priority scheme says: try to run everything to do with one diamond-DAG before working on later ones.
My gut says that although this gives quite similar results for my test workload, there will be situations where these two prioritisation schemes differ enough to care about.
Random
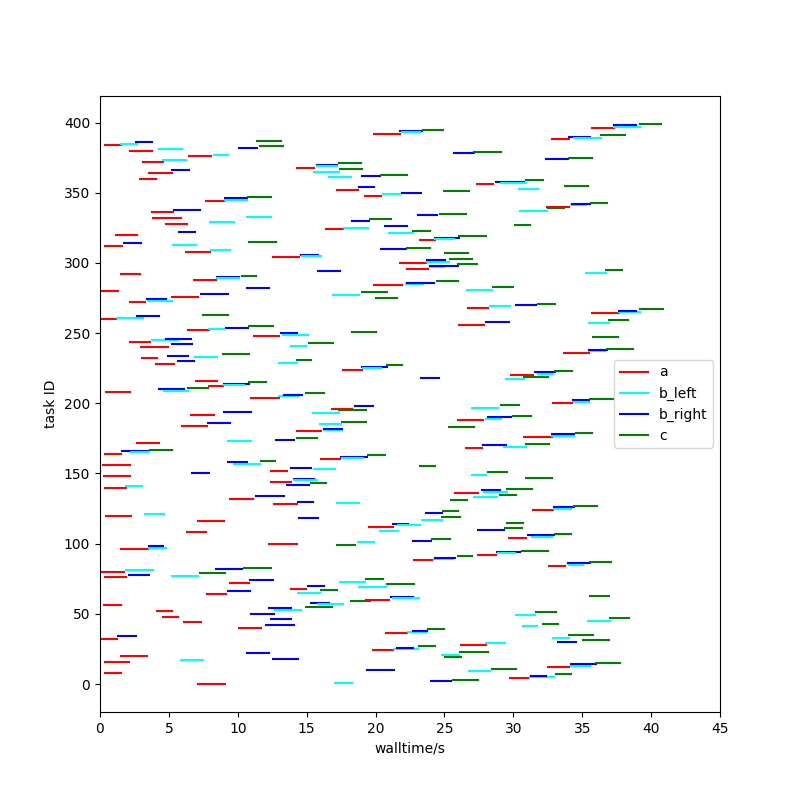
Let’s go back to the comment I made earlier about Task Vine running tasks in a more random-seeming order. Another priority scheme can make the High Throughput Executor also do this, and I think it is interesting to compare that to the above two schemes.
fa = a(parsl_resource_specification={"priority": random.random()})
fbl = b_left(fa, parsl_resource_specification={"priority": random.random()})
fbr = b_right(fa, parsl_resource_specification={"priority": random.random()})
fc = c(fbl, fbr, parsl_resource_specification={"priority": random.random()})
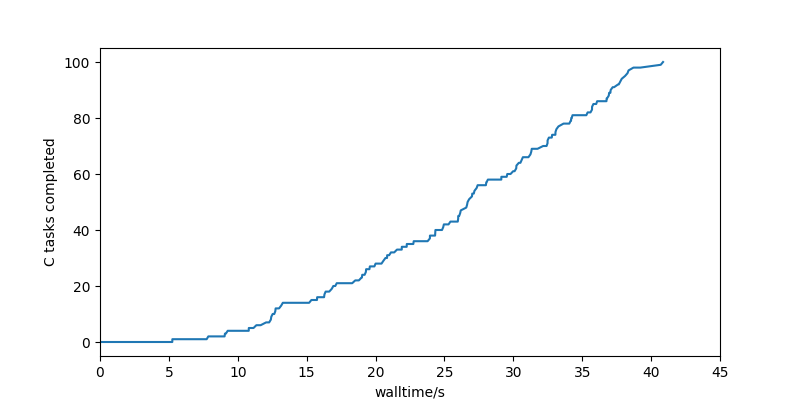
This gives a much more chaotic looking task graph, but the time-to-first-C-completion is surprisingly good: at 5 seconds, it is much closer to the principled schemes above than the default behaviour of the High Throughput Executor, although the curve is lower than those schemes for the rest of the run.
More
So there are three different schemes that work towards getting results earlier in the run.
This post and my previous one have shown that at least these two quite different goals can be expressed through a very simple language of linear priorities attached to individually to tasks, using application level knowledge to generate the priorities but then without Parsl needing to understand anything more.
I mentioned last time that some of the High Throughput Executor work was done as part of a project by Matthew Chung. The second half of that work looked at what kind of goals cannot be expressed as task priorities. An example is a goal to empty out unnecessary batch jobs so they can be terminated, rather than the High Throughput Executor’s default behaviour of spreading work evenly across all running jobs.
Parsl issue #3323 has a few other use cases related to this work.