Reduce wasted batch job time with task priority
08 Nov 2025 - Ben Clifford
What
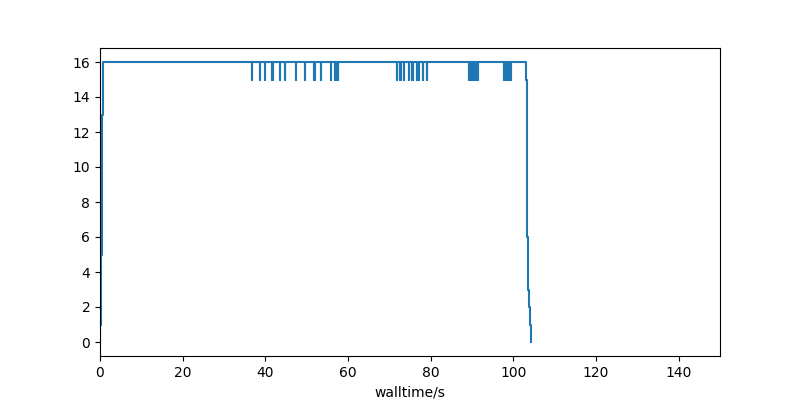
Here’s a fake run of 80 tasks of random duration, running with 16 cores:

It shows initial promise: 16 cores are fully utilised. But just after half-way through the run, utilisation drops off quite fast, leaving a lot of unused cores. Cores that you’re still paying for in allocation credits or cloud dollars.
What if that last bit of work could somehow fold up to fit into the wasted cpu-time more efficiently. Something like this:
That finishes much earlier, and drops the wasted cpu-time from around 28% to around 5% with the end-of-workload tailoff hardly happening at all. (An admission, I chose this workload to give nice plots and stats. Your workload will be different)
Let’s look at what the 80 tasks are doing in that first plot:
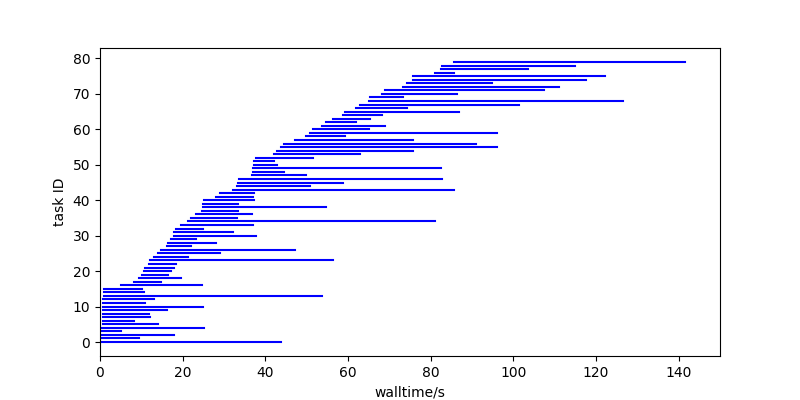
Towards the end of the run, the workload hasn’t finished because of a handful of long running tasks that stick out beyond the bulk of the workload. The solution here is to try to get those tasks to run earlier on, so that the tasks left at the end are shorter and only stick out a little bit:
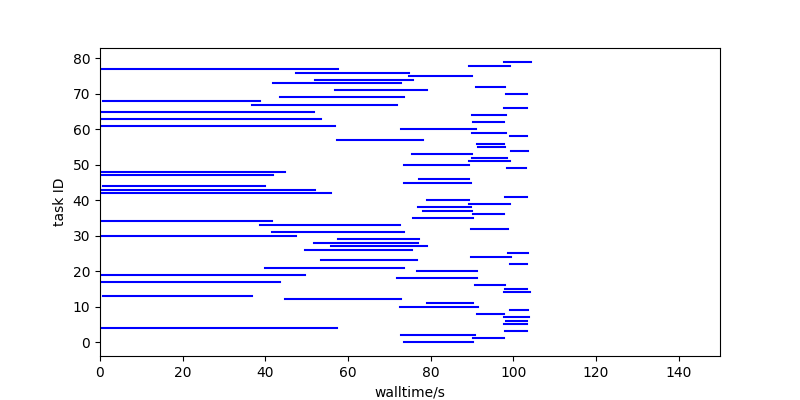
In this run, the tasks are run strictly in duration order with the longest running first, and the smaller tasks kept until later. That lets them fill in available CPU time more easily than longer tasks can.
How
To do this, you need two things:
i) you need to be able to estimate your task duration: this doesn’t have to be perfect, but what is important is that you estimate enough to pick out the long tasks accurately: your efficiency is destroyed by accidentally letting a long task be run near the end.
ii) you need to tell your Parsl executor the task duration, as a task priority - so that longer tasks will be prioritised over shorter tasks. Two Parsl executors work well for this, the High Throughput Executor and the Task Vine Executor. (Unfortunately the behaviour of priorities in the Work Queue Executor which used to work well for this use case, has changed in recent times to not help at all, so while you can try this out with Work Queue too, you’ll probably be frustrated)
In pure Parsl code, that looks like:
- enable resource specifications on your apps by
adding a
parsl_resource_specificationkeyword argument:
@parsl.python_app
def sleeper(t, parsl_resource_specification={}):
...
Your app doesn’t need to do anything with that new argument, as it will be inspected earlier on as the task flows through Parsl.
-
Add a resource specification at app invocation time:
For example, to specify a constant priority of 100:
future = sleeper(duration,
parsl_resource_specification={"priority": 100})
Replace that 100 with your own priority estimation.
Frustratingly, priorities flow in opposite directions between High Throughput Executor and Task Vine: in High Throughput Executor, the lower priority numbered tasks run before the higher priority numbered task (think: priority 1 is more important than priority 2). In Task Vine, the higher priority numbered tasks run before the lower priority numbered tasks (think: priority 1000 is more priority than priority 0.1)
So for the graphs here, using the High Throughput Executor, I set the priority to the negative of the duration: a -60 priority is more important than a -2 priority, so a 60 second task will run before a 2 second task. For Task Vine, I did it the other way round and did not negate my estimate.
If you’re using Task Vine, you might already be giving
a resource specification for other scheduling parameters
such as memory usage. In that case, add priority as
another entry in the specification dictionary.
Caveats:
Here are some issues I’ve encountered:
-
Other task metrics will change: for example, the completion rate will be much slower than average at the start and much faster than average at the end. Don’t panic if your metrics look different, and take the time to understand why.
-
You need a queue of tasks to prioritise. In some workloads, there isn’t a meaningful queue - for example, because long tasks are structured late in a workflow as dependencies of all the short tasks. If the tasks can’t run because of dependencies, they can’t be moved around in the task queue that they aren’t in yet.
-
If you’re using other Task Vine resource specs, remember that tasks have to fit into whats available. Shorter tasks might run earlier because they’re all that’s available to fill the resources right now. That’s probably ok, because you probably want to run something rather than nothing.
-
You need to be able to estimate your task durations. This doesn’t need to be perfect but if you can’t tell Parsl which tasks are the long ones, Parsl can’t prioritise them. When experimenting with this test workload , a 1 bit “long” or “short” distinction still gave noticeable improvement, but misclassifying “long” tasks as “short” was a big hit to efficiency.
Bugs discovered while writing this post:
-
Work Queue prioritisation doesn’t work well with this any more. See cctools issue #4276.
-
Parsl Visualization has a race condition/data model ambiguity when using fast task executors (i.e. the ThreadPoolExecutor). See Parsl issue #4021
Work leading to this post
In 2010, the group working on Swift, the immediate predecessor of Parsl, looked at this problem - with a slightly different angle. That resulted in a paper: Scheduling many-task workloads on supercomputers: Dealing with trailing tasks, at the 3rd Workshop on Many-Task Computing on Grids and Supercomputers. DOI 10.1109/MTAGS.2010.5699433
Starting in 2024, I began to track ideas that came up when talking to people around the general topic of selecting both tasks and workers in a richer way than Parsl’s High Throughput Executor at the time, as Parsl issue #3323.
Later that year, Matthew Chung worked on a project to implement ideas from the above two artefacts in the High Throughput Executor codebase. That resulted in the High Throughput Executor implementation of the priority resource specification in Parsl pull request #3848, and a SuperComputing 2024 poster on his wider project.
At the same time, the Work Queue Executor got the ability to pass priorities through to Work Queue itself in Parsl pull request #2067 and the Task Vine executor has had this functionality since Task Vine was first interfaced to Parsl in Parsl pull request #2599.