An Efficiency Evaluator for Parallel Scripting (EEPS) for Parsl
16 Aug 2021 - Ved Kommalapati and Ananth Hariharan
Hello! Our names are Ved Kommalapati and Ananth Hariharan and we are seniors at Normal Community High School in Normal, Illinois. We are both passionate about computer science and its applications in research. We both also plan on pursuing careers in the computer science field and we believe that this research opportunity helped us widen our horizons and gain experience in applying our computer science knowledge in research.
Overview
EEPS, or the Efficiency Evaluator for Parallel Scripting, serves as an important tool for users to evaluate the costs and efficiency associated with running parallel scripted applications. It evaluates the speed and cost of running the user’s code based on the number of workers used. The information is provided in lists and as a graphical output that helps the user understand and evaluate the best core-to-cost and core-to-time ratios for them.
Purpose
EEPS enables one to test several different cores-per-worker values for the same Python-based applications (that connect and have a ‘total’ statement). EEPS will provide graphs so one can evaluate how many workers they believe are necessary for their specific use case. EEPS will not suggest a specific value, as companies and programs have different goals. Rather, it provides graphs that provide you information regarding how the number of workers affects the cost and runtime of their compilation of applications.
How to use
After reading the comments on eeps.py and replacing the lines of code that we indicated (you can run with our apps as well and skip the replacement step), run eeps.py.
Although this run may take a long time, it will enable you to save time for future tests as you can determine the number of workers you plan on using for your compilation of apps forever.
After determining a select few numbers of workers that you may want to test, instead of re-running eeps.py, you can run singleCpwTest.py with your select values. Read the comments to know where to enter/replace these values.
Results
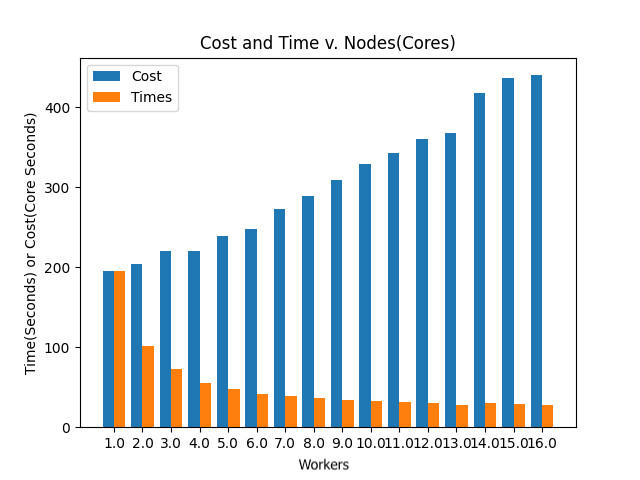
The first graph displays how increasing the number of workers impacts how cost and runtime change. This graph is specific to our apps and total compilation function. Based on this graph, one can notice that as the number of workers increases, there is more loss despite the time decreasing. If one’s applications are uniform and require a fixed number of workers at all times, the blue bars will create a flat line or asymptote while the times decrease. This graph can be used so one can determine how many workers they want to use. Our program prints suggested values as the cheapest and the fastest, but one can choose for themself while analyzing the graph.
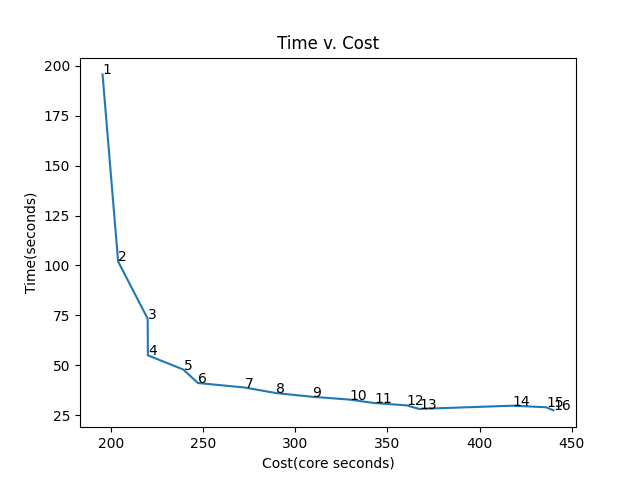
The second graph displays the relationship between cost and time as the number of workers increases. The number next to the data points states the number of workers for the specific run. This graph can be used to understand how much time and cost change as the number of workers is altered. In our case it seems like after about 4 or 5 workers, there is little change in time and a lot of change in cost. Hence, if efficiency and decent speed is our priority we would use 4 or 5 workers for our specific compilation of apps. If speed is our only priority and efficiency does not matter, 16 workers is a viable option as well.
Overall, we wanted to provide graphs that provide the necessary information for one to make their own decisions based on their needs.
Problem we faced
During our research, however, we did face an obstacle. During our development of eeps.py, we wanted to change the cores_per_worker in the config. However, we were just resetting the variable and failing to actually reset the config. After analyzing our data and graphs, we came to notice this. Hence, we altered our loop to reload the configuration with the new cores_per_worker value for each loop iteration. We also made the fresh_config function have a parameter so we could pass the value from the cpw list as the new cores_per_worker. In order to make this work, we also had to dfk.cleanup() and clear() the parsl config at the end of each loop iteration.
Skills learned
During our research, we also gained several invaluable skills. We learned how to properly use git commands. We learned how to interact with Linux machines and use the command line and terminal. We also learned how to use the scp protocol to recover files from a cloud machine to our personal desktops. We also became more experienced in Python and SQL throughout this experience.
We would also like to thank Dr. Daniel S. Katz and Mr. Ben Clifford for their help.